
Меню сайта
Наши новости
Распространение алкалоидов в растительном мире.
Умягчение воды
КлассификацияДипломы, курсовые и прочее / Расчет квантово-химических параметров ФАВ и определение зависимости "структура-активность" на примере сульфаниламидов / Математические методы расчета
констант органических молекул и видов проявляемой физиологической активности / Дипломы, курсовые и прочее / Расчет квантово-химических параметров ФАВ и определение зависимости "структура-активность" на примере сульфаниламидов / Математические методы расчета
констант органических молекул и видов проявляемой физиологической активности / Классификация Классификация
Представление о кластеризации объектов в пространстве информативных измерений является центральным в приложениях методов распознавания образов. Нахождение такого преобразования, с помощью которого можно кластеризовать исследуемую выборку и в результате получить классы объектов, обладающих заданным свойством, является общей целью процедур измерения, предварительной обработки и априорного отбора признаков. По существу, распознавание образов является методом выявления сходства между исследуемыми объектами. В результате классификации отыскиваются некоторые соотношения, характеризующие это сходство. Существует много различных методов классификации, однако в фармакологических приложениях преимущественно используются непараметрические методы. Для понимания основ непараметрических методов необходимо небольшое введение в теорию параметрических методов.
Параметрические методы классификации основаны на байесовской статистике. Эти методы формируют классификационное правило непосредственно из вероятностного распределения данных. Вид вероятностного распределения данных зависит от типа и числа датчиков, методов предварительной обработки и отбора признаков. Цель классификации заключается в максимальном увеличении доли правильных классификаций путем построения функции, определяющей границы между различными классами.
Классификатор может быть построен непосредственно из формулы Байеса
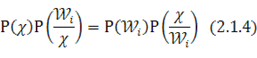
В этом соотношении X - вектор-образ, компоненты которого получены в результате работы различных датчиков. Численные значения этих компонент определяют распределение данных в N-мерном пространстве. Функция Р (Х) описывает распределение данных независимо от того, к какому классу они принадлежат. Р (![]() ) — вероятность наблюдения класса Wi. Р(W/X) - условная вероятность того, что вектор X принадлежит классу Wi. P(X/Wi) — условная вероятность того, что из класса Wi будет выбран объект, описываемый вектором-образом X.
) — вероятность наблюдения класса Wi. Р(W/X) - условная вероятность того, что вектор X принадлежит классу Wi. P(X/Wi) — условная вероятность того, что из класса Wi будет выбран объект, описываемый вектором-образом X.
Смотрите также
Исследование электрохимического поведения ионов самария в хлоридных и хлоридно-фторидных расплавах
...
Алхимия как феномен культуры
На современном
этапе научное познание мира происходит в соответствии с концепцией
естествознания — совокупности естественных наук, которые изучают явления и
процессы, происходящие в мире, в ...